Unlocking the Potential of Reinforcement Learning in Improving Reasoning Models
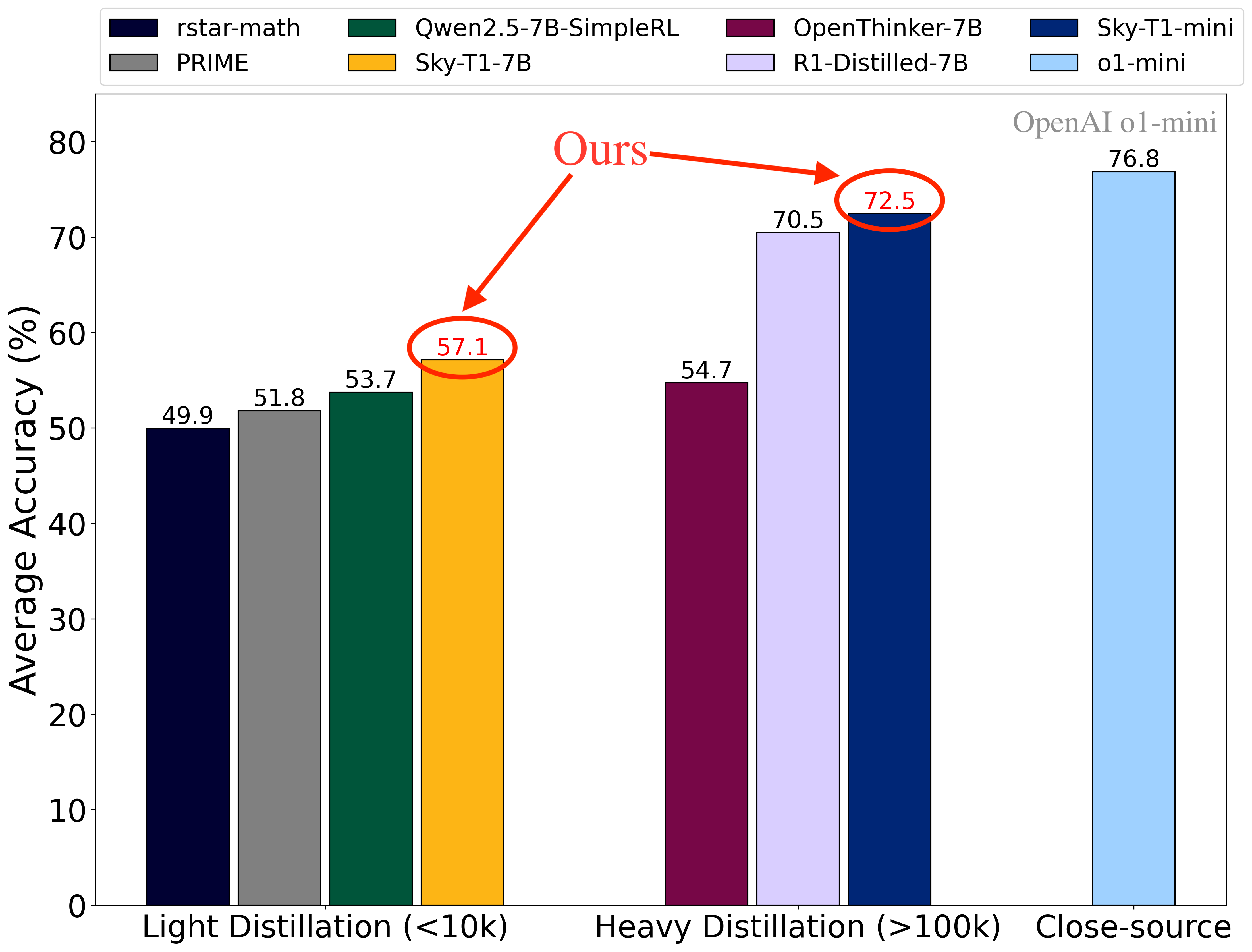
Figure 1: Average accuracy of different models on four popular math reasoning tasks (i.e., AIME24, AMC23, MATH500, and OlympiadBench). Sky-T1-7B demonstrates SOTA performance among 7B models (left 4 bars) trained with <10k distilled samples from strong teacher reasoning models and Sky-T1-mini reaches SOTA performance among all open-source 7B models, including those (5th-7th bars) trained with >100k distilled samples from strong teacher reasoning models. *For rstar-math and Qwen2.5-7B-SimpleRL, since the model weights are not open source, we directly use their reported numbers.
By: Shiyi Cao, Shu Liu, Dacheng Li, Tyler Griggs, Kourosh Hakhamaneshi, Sumanth Hegde, Eric Tang, Shishir G. Patil, Matei Zaharia, Joey Gonzalez, Ion Stoica — Feb 13, 2025
We are excited to release Sky-T1-7B, a SOTA open-recipe 7B model on math reasoning tasks, trained with 4-step SFT->RL->SFT->RL from the Qwen2.5-Math-7B base model. We also release Sky-T1-mini, trained with simple Reinforcement Learning (RL) applied on top of the DeepSeek-R1-Distill-Qwen-7B model, achieving close to OpenAI o1-mini performance on popular math benchmarks.
In this blog post, we also introduce a series of RL-enhanced 7B models we trained using different recipes to develop a deeper understanding of the potential of reinforcement learning in enhancing model capabilities and its relationship with Supervised Fine-Tuning (SFT). In summary, in this blog post:
- We show that RL can significantly improve the reasoning scores of a small model.
- We demonstrate a recipe for training Sky-T1-7B with RL and SFT from the Qwen2.5-Math-7B base model using only 5k distilled data from a strong teacher model QwQ, outperforming models trained with over 100k distilled data from a much stronger teacher model DeepSeek-R1 (e.g., OpenThinker-7B trained on 117k R1 responses). We open-source the training recipe and its artifact, Sky-T1-7B. Notably, Sky-T1-7B also reaches similar OlympiadBench performance as DeepSeek-R1-Distill-Qwen-7B, which is trained on 800K data distilled from DeepSeek-R1.
- Second, we show that simple RL can further enhance the current SOTA 7B reasoning model DeepSeek-R1-Distill-Qwen-7B’s capability, resulting in a new SOTA open-weights 7B reasoning model Sky-T1-mini, with close to o1-mini performance. The training takes 36 hours using 8xH100s, which is around $870 according to Lambda Cloud Pricing.
- We conduct a series of ablation studies on SFT data scaling, RL scaling and model’s pass@k performance after SFT and RL. We observe that the Long CoT SFT in general enhances the model’s pass@k performance while RL lifts the model’s performance at lower generation budgets (i.e., pass@1), which sometimes come at a cost of the entropy of solutions.
To foster community progress, we open-sourced all artifacts including the training code, training recipes, model weights, and evaluation scripts.
- Github: Code for data generation, SFT, reinforcement learning training, and evaluation.
- HuggingFace: The Huggingface collection for model checkpoints, final model weights and datasets used for Sky-T1-7B and Sky-T1-mini.
Sky-T1-7B – Trained with 4-step SFT and RL
 Table 1: Benchmark performance of the intermediate models trained in the 4-step pipeline. The final model achieves accuracy improvement of +10.4% on AIME24, +33.2% on MATH500, +36.8% on AMC23, +32.1% on OlympiadBench, and +21.1% on average, compared to the base model.
Table 1: Benchmark performance of the intermediate models trained in the 4-step pipeline. The final model achieves accuracy improvement of +10.4% on AIME24, +33.2% on MATH500, +36.8% on AMC23, +32.1% on OlympiadBench, and +21.1% on average, compared to the base model.
Step 1: SFT
We use the QwQ model to generate the distillation data since the model was trained before the release of DeepSeek R1 and QwQ was the only open-weights long reasoning model at the time when we trained the model. For the data mixture, we use GPT-4o-mini to classify the difficulty of the prompts according to the AoPS standard and selected math problems of difficulty higher than Level 3, Olympiads higher than Level 8, and all AIME/AMC problems in the NUMINA dataset. We then perform rejection sampling by only accepting the solutions that match the ground truth. In total, we curated 5K responses from QwQ. Finally, we use the 5K responses to perform SFT on the Qwen2.5-Math-7B using the Sky-T1 system prompt. We trained the model for 3 epochs, using a learning rate of 1e-5, and a batch size of 96. After this stage, we get the Sky-T1-7B-Step1 model.
Step 2: RL
Next, we apply the PRIME’s algorithms to it. We use the Eurus-2-RL-Data for the RL training and run it for 127 steps with a batch size of 256 (~30K data). For each prompt, we generate 4 rollouts and adopt the prompt filtering optimization proposed in PRIME that filters out the problems for which all of the 4 rollouts are correct or wrong. After this stage, we get the Sky-T1-7B-Step2 model. This stage runs on 8xH100 for around 44 hours.
As suggested in DeepSeek-V3 technical report’s sec 5.1, the model trained through SFT and RL can serve as a high-quality data generator. We therefore perform another round of distillation and rejection sampling on traces generated by Sky-T1-7B-Step2 and curated 5k SFT samples using the same data mixture in Step 1. We fine-tune the Qwen2.5-Math-7B with these 5k samples and obtained the Sky-T1-7B-Step2-5k-distill model, which surprisingly maintains similar or even better performance than Sky-T1-7B-Step2 across the 4 benchmarks, demonstrating extremely high data-efficiency compared to the model fine-tuned with 5k QwQ traces.
Step 3: SFT Again
Together, with the 5K data distilled from Sky-T1-7B-Step2 in Step 2 and 5K data distilled from QwQ in Step 1, we perform another round of SFT on Qwen2.5-Math-7B base model. Similarly, we trained the model for 3 epochs, using a learning rate of 1e-5, and a batch size of 96. We then get the Sky-T1-7B-step3 model.
Step 4: RL Again
In this stage, to speed up the RL training, we adopt the simple RLOO algorithm without using prompt filtering and process reward model. We use the numina_amc_aime and numina_olympiads subset of the Eurus-2-RL-Data. We run the training for 59 steps with a batch size of 256 (~15K data). For each prompt, we generate 8 rollouts. We get Sky-T1-7B as the final model.
Evaluation
For reproductivity, we perform all the evaluation using the Qwen’s math evaluation suite. For AIME24 and AMC 23, since they only have 30 and 40 questions respectively, we evaluate their performance by sampling 8 times for each question with a temperature of 0.6 and a top-p sampling probability of 0.95 and then compute the pass@1 (the calculation script is also provided here). For MATH500 and OlympiadBench, we use greedy decoding.
Results
We report the benchmark results for models after each stage as well as the intermediate distilled model in Table 1. We also plot the models’ pass@k curves to better understand how each SFT and RL stage impacts the model’s internal capability. For comparison, we conduct another ablation experiment which runs the RLOO directly on the Qwen2.5-Math-7B base model using the STILL3 dataset, with 4 rollouts for each prompt. We train for 104 steps and get the final model as Sky-T1-7B-Zero.
As shown in Figure 2, Long CoT SFT significantly improves the model’s overall pass@k performance in both AIME24 and AMC23. In AMC, the two-stage RL primarily boosts pass@1 accuracy while reducing the diversity of solutions for k = 4 to 32. In AIME, the step4 RL further enhances overall pass@k compared to the step1 SFT and step2 RL, though its impact is less pronounced compared to Sky-T1-7B-Zero.
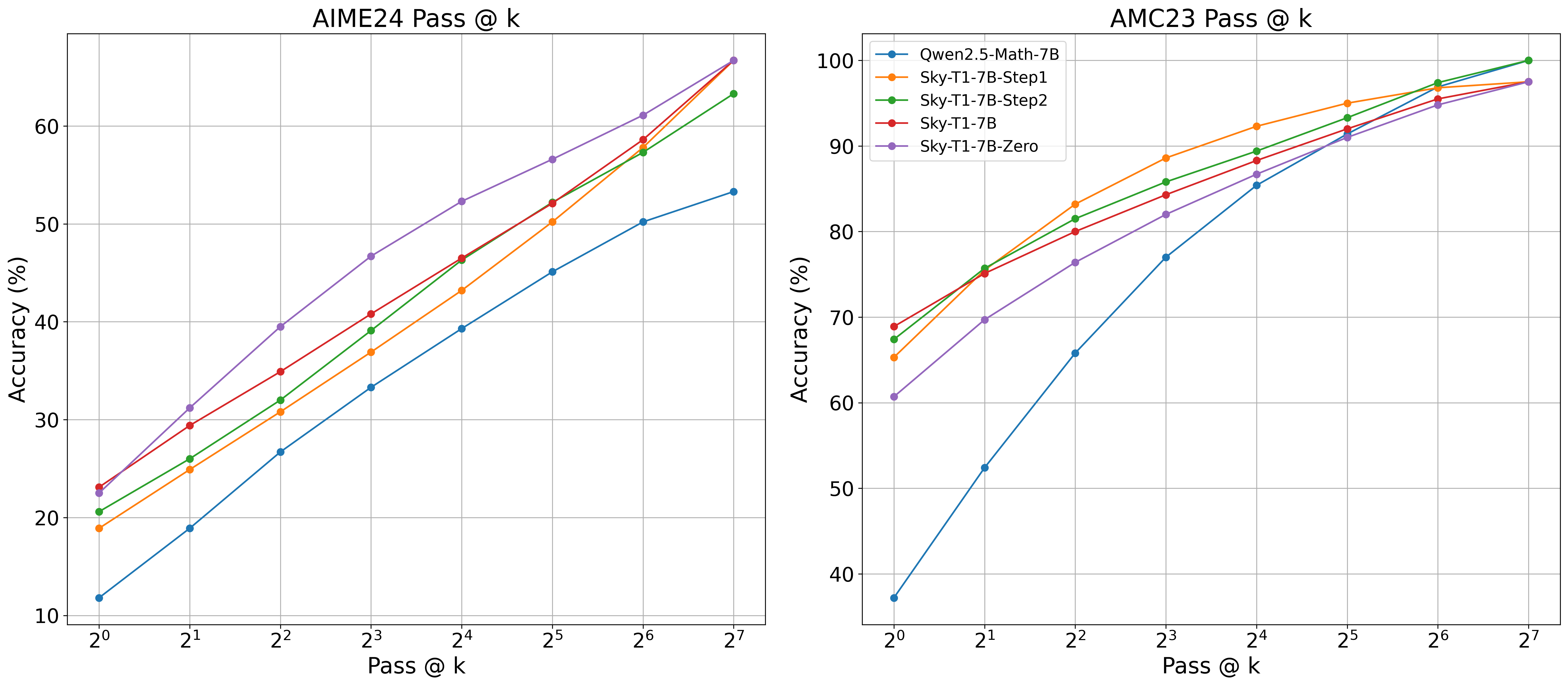 Figure 2: Pass@K curves for models trained after each step for AIME24 and AMC23.
Figure 2: Pass@K curves for models trained after each step for AIME24 and AMC23.
Sky-T1-mini – Simple RL Boosts the Performance
Throughout our development of Sky-T1-7B (which was trained before the release of DeepSeek R1’s release), we found that simple RL algorithms without a Process Reward Model (PRM) work well to enhance the model’s performance. Therefore, we also apply the simple RLOO algorithm with only the verifier reward on DeepSeek-R1-Distill-Qwen-7B, the current SOTA open-source 7B reasoning model, using the STILL3 dataset and the numina_amc_aime and numina_olympiads subset in the Eurus-2-RL-Data dataset. We run it for 119 steps (~28 hours) with a batch size of 256 (~30k) on 8xH100, with a cutoff length of 8k and then run it for 29 steps (~8.7 hours) with a cutoff length of 16k. The final model, Sky-T1-mini, approaches o1-mini performance across the four math benchmarks, as reported in Figure 3. While we only trained the model for a short period of time with contexts cutoff (we also didn’t carefully choose the algorithms and data mixtures), the accuracy improvement is still impressive: +4% on AIME, +5.6% on OlympiadBench and +2% on average, demonstrating the potential of RL in further enhancing model’s performance beyond distillation.
Complete Results
 Figure 3: Accuracy of Sky-T1-7B and Sky-T1-mini on AIME23, AMC23, MATH500, and OlympiadBench, compared with other 7B models.
Figure 3: Accuracy of Sky-T1-7B and Sky-T1-mini on AIME23, AMC23, MATH500, and OlympiadBench, compared with other 7B models.
Other Observations
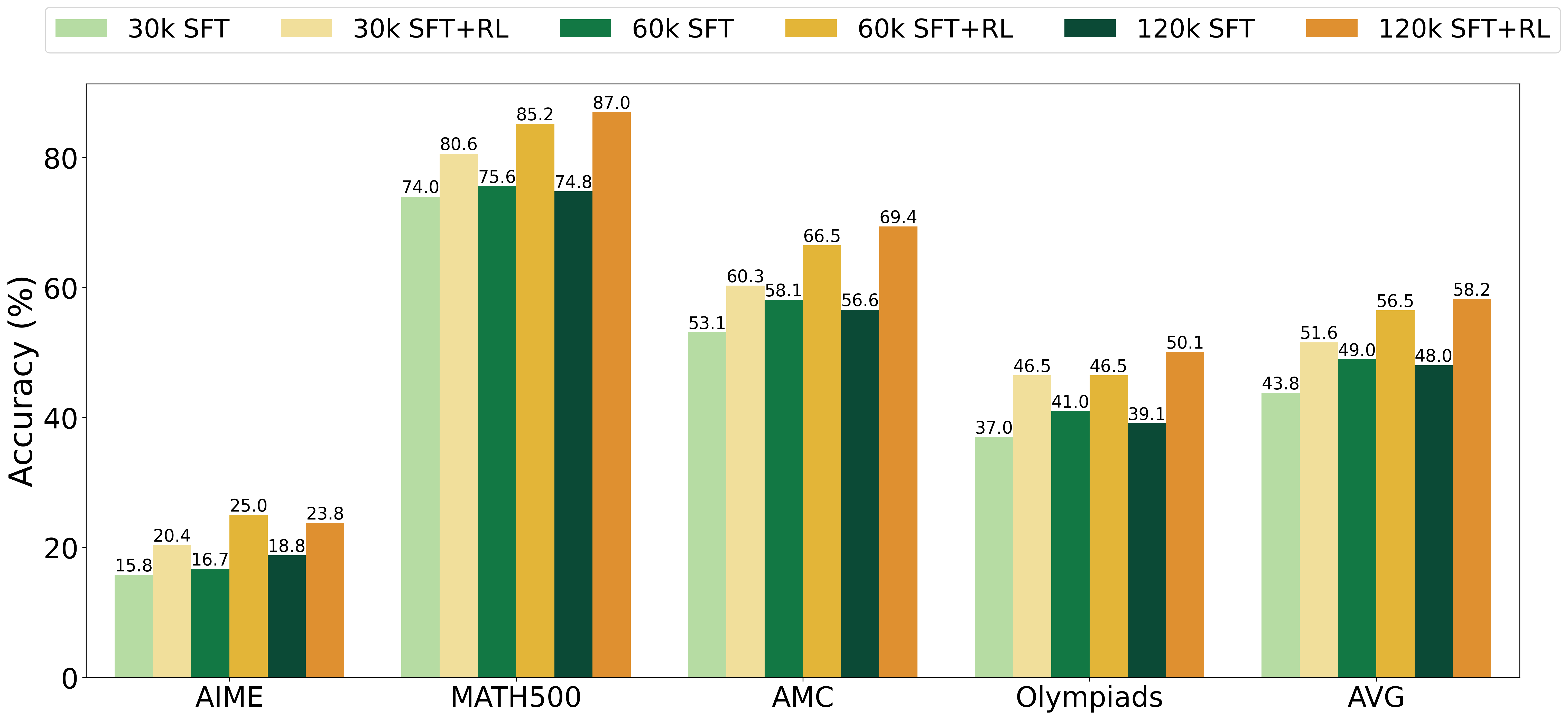 Figure 4: Benchmark performance of models trained with different sizes of SFT data and those further enhanced with RL.
Figure 4: Benchmark performance of models trained with different sizes of SFT data and those further enhanced with RL.
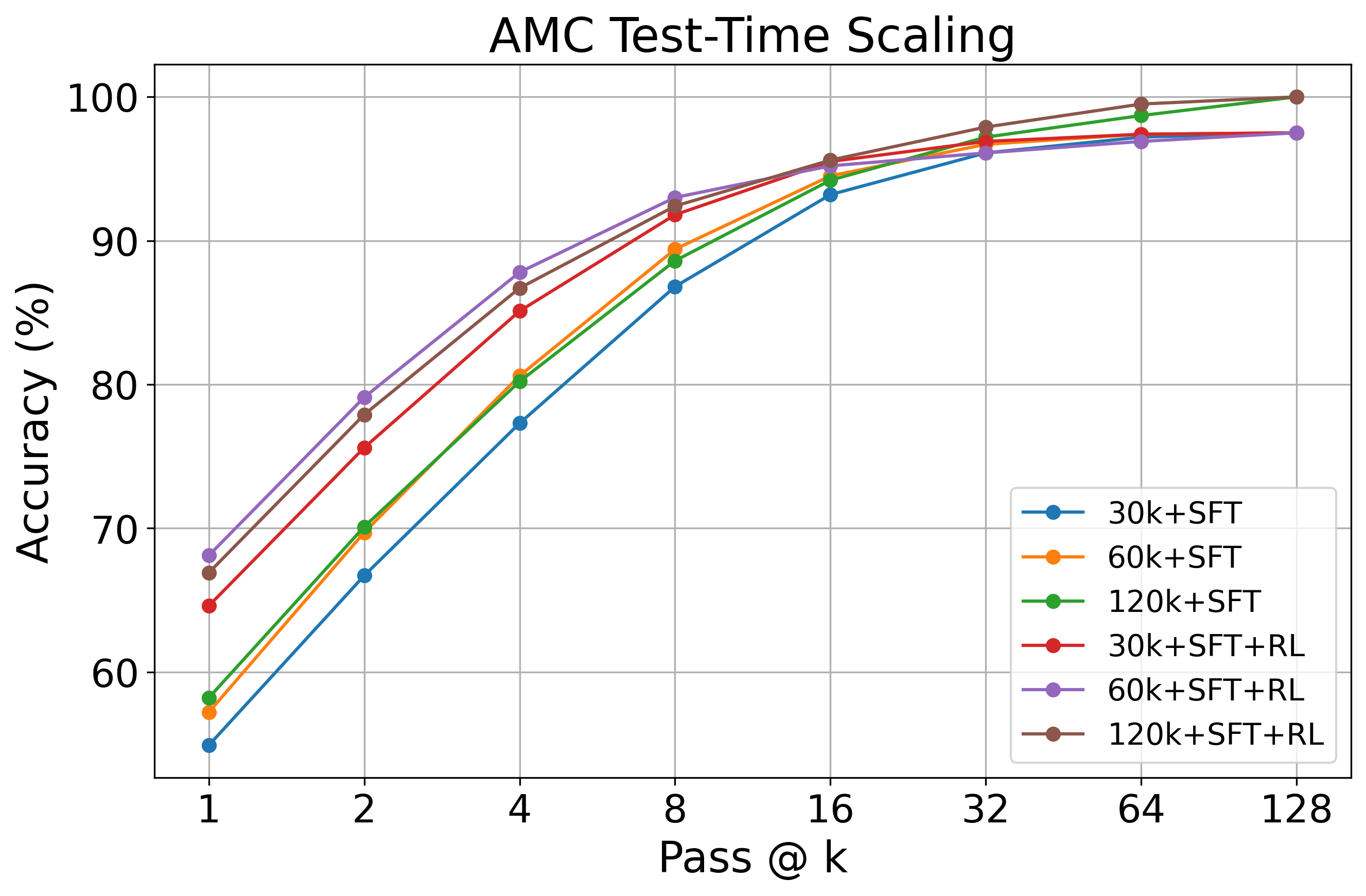 Figure 5: Pass@K curves for models trained with different sizes of SFT data and those further enhanced with RL for AMC23.
Figure 5: Pass@K curves for models trained with different sizes of SFT data and those further enhanced with RL for AMC23.
To evaluate the impact of scaling Long CoT SFT data sizes, we scale QwQ traces from 30k to 60k to 120k. We report the benchmark performance and AMC pass@k curves for models trained with SFT and those further enhanced with RL in Figure 4 and Figure 5 respectively. The RL training here adopts the simple RLOO algorithm, using the STILL3 dataset, with 4 rollouts per prompt.
From the benchmark performance plot as shown in Figure 4, while SFT enables scaling from 30k to 60k, its effectiveness plateaus beyond this point. In contrast, models trained further with RL continue to benefit from increased data, demonstrating further improvements when scaling up to 120k. This highlights the importance of RL in effectively leveraging additional SFT training data.
A similar pattern emerges in pass@k evaluations as shown in Figure 5. When data scales from 30k to 60k and 120k, both SFT and RL show improvement in pass@k accuracy, with RL consistently achieving better test-time scaling across data sizes than SFT. Compared to scaling from 30k to 60k, the improvements from 60k to 120k are less pronounced for both SFT and RL.
This figure also shows that RL primarily enhances efficiency by improving its pass@k accuracy at lower generation budgets (i.e., for small k), effectively lifting performance without requiring excessive sampling. However, this may come at a trade-off of entropy of solutions – less gains with extensive parallel sampling.
Conclusion
In this blog post, we show that RL can further enhance the model’s capability on either lightly- or heavily-distilled models. We further conduct the pass@k experiments to demonstrate how SFT and RL will affect the model’s pass@k performance. We observe that the Long CoT SFT in general enhances the model’s pass@k performance while RL lifts the model’s performance at lower generation budgets (i.e., pass@1), which sometimes come at a cost of the entropy of solutions.
Acknowledgement
This work is done at Berkeley Sky Computing Lab with generous compute support from Anyscale, Databricks, and Lambda Labs.
Citation
@misc{sky-t1-7b,
author = {NovaSky Team},
title = {Unlocking the Potential of Reinforcement Learning in Improving Reasoning Models},
howpublished = {https://novasky-ai.github.io/posts/sky-t1-7b},
note = {Accessed: 2025-02-13},
year = {2025}
}