Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy

By: Tyler Griggs, Shiyi Cao, Dacheng Li, Shu Liu, Shishir G. Patil, Matei Zaharia, Joey Gonzalez, Ion Stoica — Jan 23, 2025
We are excited to introduce Sky-T1-32B-Flash, our updated reasoning language model that significantly reduces overthinking, slashing inference costs on challenging questions by up to 57%.
This enhancement decreases generation length while preserving accuracy across domains such as mathematics, coding, science, and general knowledge, and requires only $275 for the complete training recipe using 8xH100s according to Lambda Cloud pricing.
To foster transparency and collaboration, we have open-sourced the full pipeline—from data generation and pre-processing to preference optimization and evaluation scripts—and openly provide the model weights and data.
- Github: Code for data generation, response rewriting, preference optimization, and evaluations.
- Dataset: 10K preference pairs
- HuggingFace: Sky-T1-32B-Flash model weights
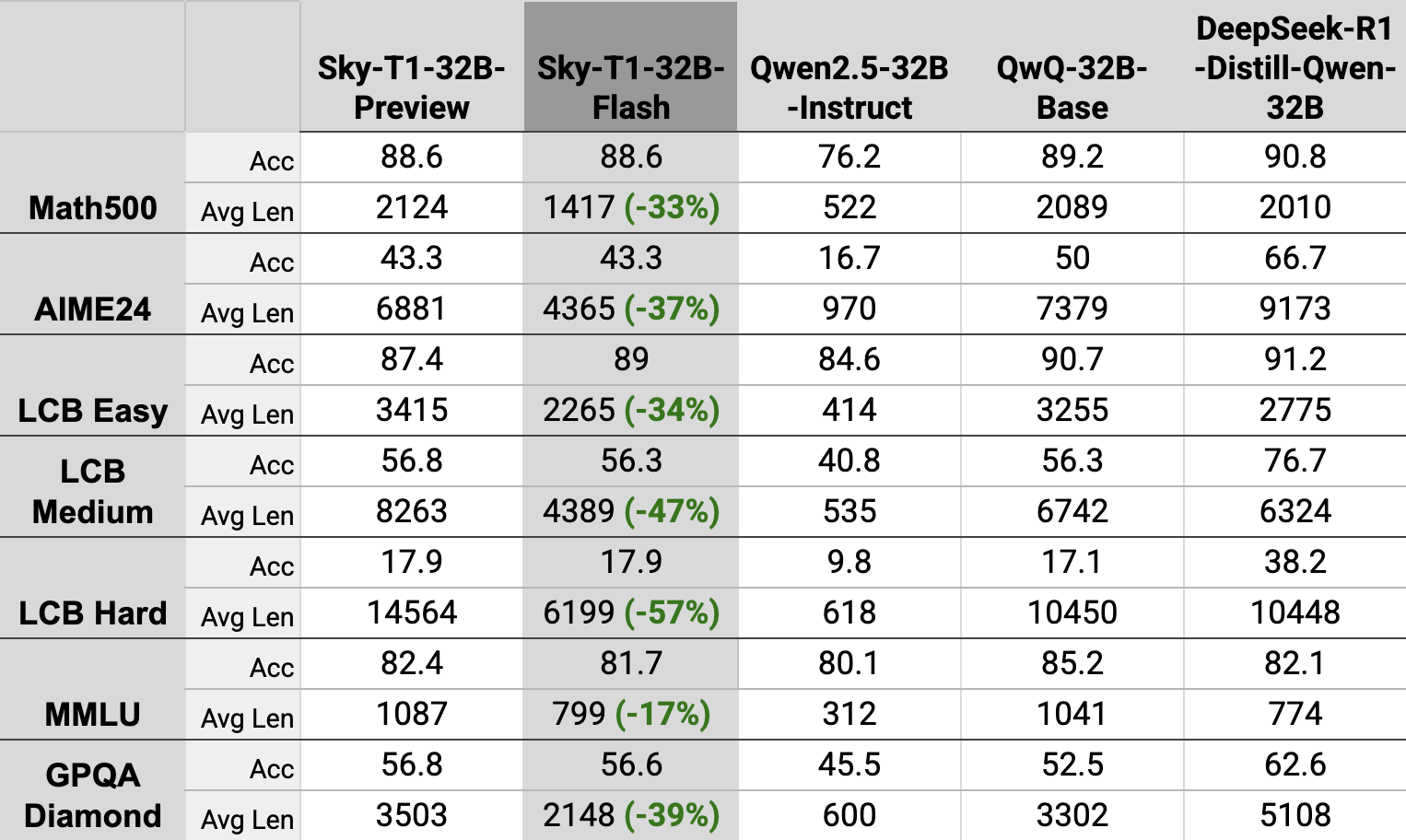
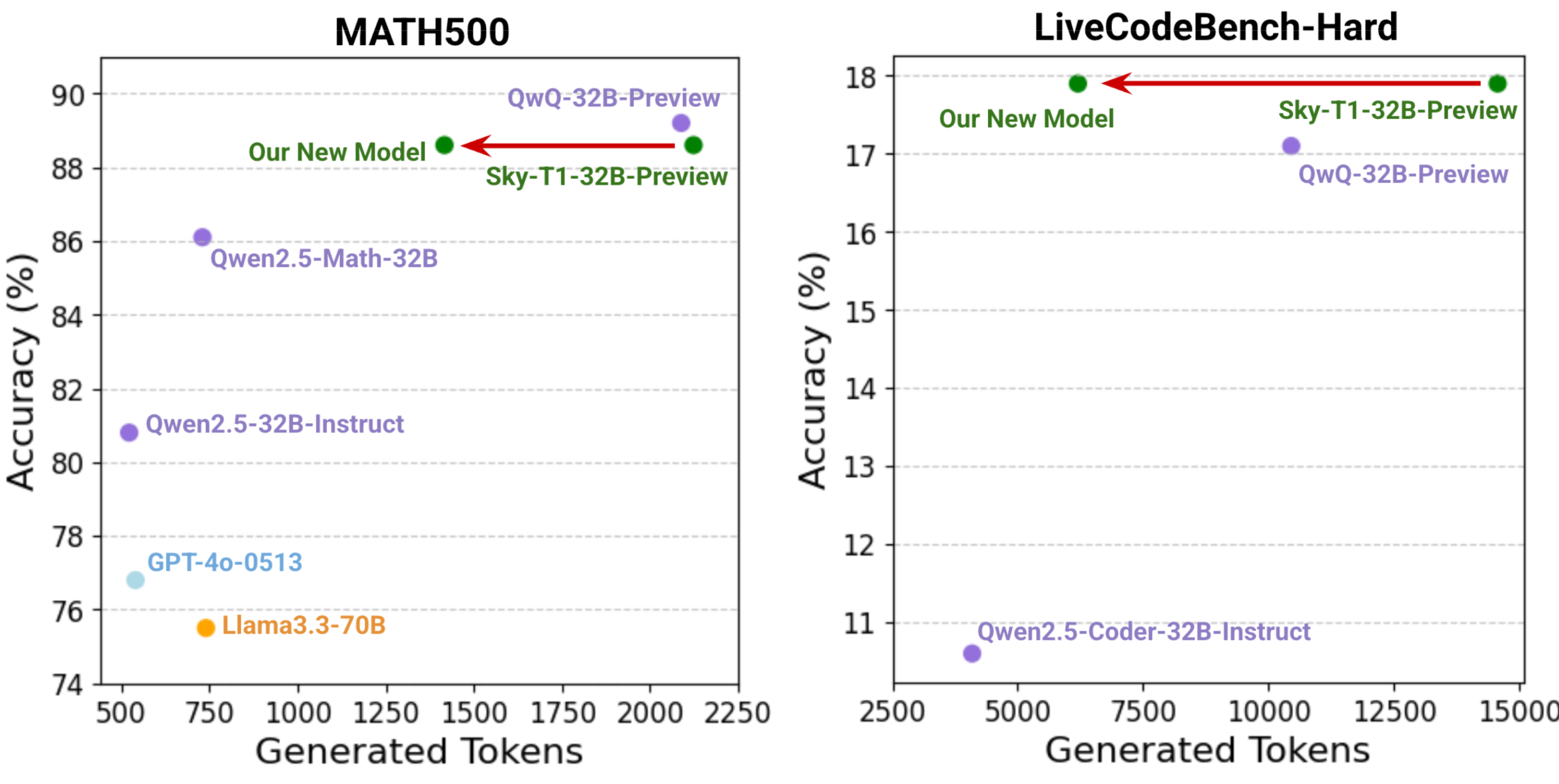 Figure 1: Our new model significantly reduces generated token lengths while maintaining strong performance on challenging benchmarks.
Figure 1: Our new model significantly reduces generated token lengths while maintaining strong performance on challenging benchmarks.
What is overthinking?
Overthinking refers to reasoning models’ tendency to produce unnecessarily long responses, often with redundant or excessive reasoning steps. In line with the findings of recent work, we observe that reasoning models, including NovaSky’s recently released Sky-T1-32B-Preview, QwQ, and R1, often produce reasoning sequences with multiple proposed solutions each followed by double-checking transitions such as “Alternatively,” “But wait,” or “Let me reconsider”. While double-checking can detect errors and refine solutions, it often results in repetitive validations of simple or already-validated steps, creating inefficiency. For example, in response to the question “What is 1+1,?” Sky-T1-32B-Preview produces over 1000 tokens and more than 10 of these double-checking transitions.
Benefits of reducing overthinking
Reducing overthinking improves efficiency and scalability by reducing redundant or unnecessary token generation. This improvement not only greatly reduces inference costs for reasoning models, but also offers multiple downstream benefits. First, the accelerated response delivery provides a much higher-quality user experience. Further, with more efficient reasoning, test-time generation methods such as Best-of-N, Majority Vote, or Monte Carlo Tree Search can yield higher accuracy within fixed computational budgets. It also streamlines data generation in self-training pipelines, which are often bottlenecked by large-scale data generation runs.
How to reduce overthinking?
Our approach to reduce overthinking builds on the self-training recipe proposed in recent work with important enhancements to improve accuracy in challenging benchmarks across multiple domains. A challenge of reducing overthinking is to prevent the model from underthinking, where the model proposes a final solution without sufficiently validating it. This challenge is especially highlighted in the most challenging benchmarks where extensive double-checking and backtracking are required. Ideally, the model learns to adjust the depth of its reasoning based on the complexity of the question.
Our training process involves three primary stages: data generation, response rewriting, and preference optimization.

Stage 1) Data Generation
We used Sky-T1-32B-Preview to generate responses to the 12K questions in the PRM800K dataset. For each question, we used a temperature of 1.0 and generated 8 responses to create a diversity of response lengths. We then formed preference pairs to contrast “verbose” vs. “concise” solutions. Specifically, from the generated responses, we picked the shortest correct response as the positive example and the longest correct response as the negative example. We discarded the rest of the generated responses, and discard any questions that did not produce at least two correct responses. We hypothesize that preference optimization over such pairs can encourage the model to reduce overthinking.
Preference optimization with these pairs reduced generation lengths and mostly maintained accuracy on several benchmarks (MATH500, GPQA, MMLU), however, we observed accuracy degradation on challenging problems in coding (LiveCodeBench-Medium and -Hard) and the most challenging math suites, AIME24 and MATH500 Level 5. These results suggest that the model was underthinking in cases requiring more complex reasoning. To address this, we used the initial dataset of 8 responses per question to add 1K preference pairs to our training data, where the negative example is the shortest incorrect response and the positive example is the shortest correct response that is longer than the negative example, ensuring the model retained its ability to engage in deeper reasoning when necessary. This new data mix brought the model back up to par with Sky-T1-32B-Preview on the most challenging math benchmarks.
Recipe Enhancement #1: Incorporate {short incorrect response, long correct response} into the preference pair dataset to encourage complex thinking for challenging problems.
Interestingly, preference optimization with this math-only dataset reduced generation length by >25% in the coding domain while maintaining accuracy on LCB-Easy. However, we observed a drop in accuracy in the more challenging benchmarks LCB-Medium and -Hard, so we added 500 more preference pairs generated by Sky-T1-32B-Preview on the TACO dataset. We again generated 8 responses with a temperature of 1.0 and created preference pairs with the shortest and longest correct responses, which elevated coding performance back to the level of Sky-T1-32B-Preview.
Recipe Enhancement #2: Incorporating a small number of coding preference pairs simultaneously boosts coding accuracy and further reduces coding generation lengths.
Stage 1 required ~8 hours on 8xH100-80GB for a total of ~$190 according to Lambda Cloud pricing.
Stage 2) Response Rewriting
We refined positive samples by removing unnecessary sub-solutions. The model’s reasoning sequences often include multiple proposed solutions each followed by double-checking transitions such as “Alternatively…,” “But wait…,” or “Let me reconsider…”. For easier questions, these transitions rarely lead to an altered answer but can extend the response length significantly. Using techniques inspired by recent work, we use Llama3.3-70B to separate the solutions within a response then rewrite the response to include only the first correct sub-solution (FCS) and one additional sub-solution (+1). This pruning approach removes most of the unnecessary sub-solutions, reducing the sequence length of positive samples, but includes a single additional sub-solution to maintain the model’s long chain-of-thought reasoning structure.
Following prior work, we also explored rewriting the response to include up to the first correct solution (FCS) or up to the second correct solution (FCS+Reflection), but found our FCS+1 approach to achieve lowest generation lengths while maintaining accuracy. For coding samples, we did not perform response rewriting. We could not apply our FCS+1 approach to coding because responses almost never propose multiple complete code blocks as solutions, though we believe there is opportunity to remove significant redundancy in coding responses. We have open-sourced the response rewriting pipeline to enable researchers to easily explore alternative methods.
Recipe Enhancement #3: Rewriting positive preference math examples to maintain only the first correct solution and one additional solution (FCS+1) maintains accuracy (unlike FCS) and produces shorter generation lengths (relative to FCS+R).
Stage 2 required ~1 hour on 8xH100-80GB for a total of ~$25 according to Lambda Cloud pricing.
Stage 3) Preference Optimization
We employed SimPO for preference optimization. SimPO is closely related to DPO, but incorporates a length-normalized implicit reward into the optimization approach, which leads to shorter sequence lengths relative to DPO. Further, SimPO eliminates the need for the reference model required by DPO, making preference optimization less compute-intensive and therefore cheaper. As an alternative to preference optimization, we also explored using only SFT with the shortest responses, but found sequence lengths were only marginally reduced (<5%). In the ablation results, we include ablations for DPO using the same preference pairs as described in Stage (2) and for SFT using the shortest responses.
We start with Sky-T1-32B-Preview as our base model and train with SimPO for 1 epoch and a batch size of 96. We found SimPO results to be sensitive to hyperparameter settings and performed limited exploration within the following space: learning rate = {1e-7, 5e-7, 1e-6}, gamma = {0.3, 0.5, 1.0}, beta = {2.0, 2.5}. We achieved the best performance with a learning rate of 5e-7, gamma of 0.3, and beta of 2.0. We use Llama-Factory to perform training.
Stage 3 required ~2.5 hours on 8xH100-80GB for a total of ~$60 according to Lambda Cloud pricing.
Results
Sky-T1-32B-Flash maintains Sky-T1-32B-Preview’s accuracy across the suite of challenging benchmarks, and consistently reduces generation lengths by over 30%. Even on the most challengine problems, from AIME24 and LCB-Hard, Sky-T1-32B reduces sequence lengths by 37% and 57%, respectively.
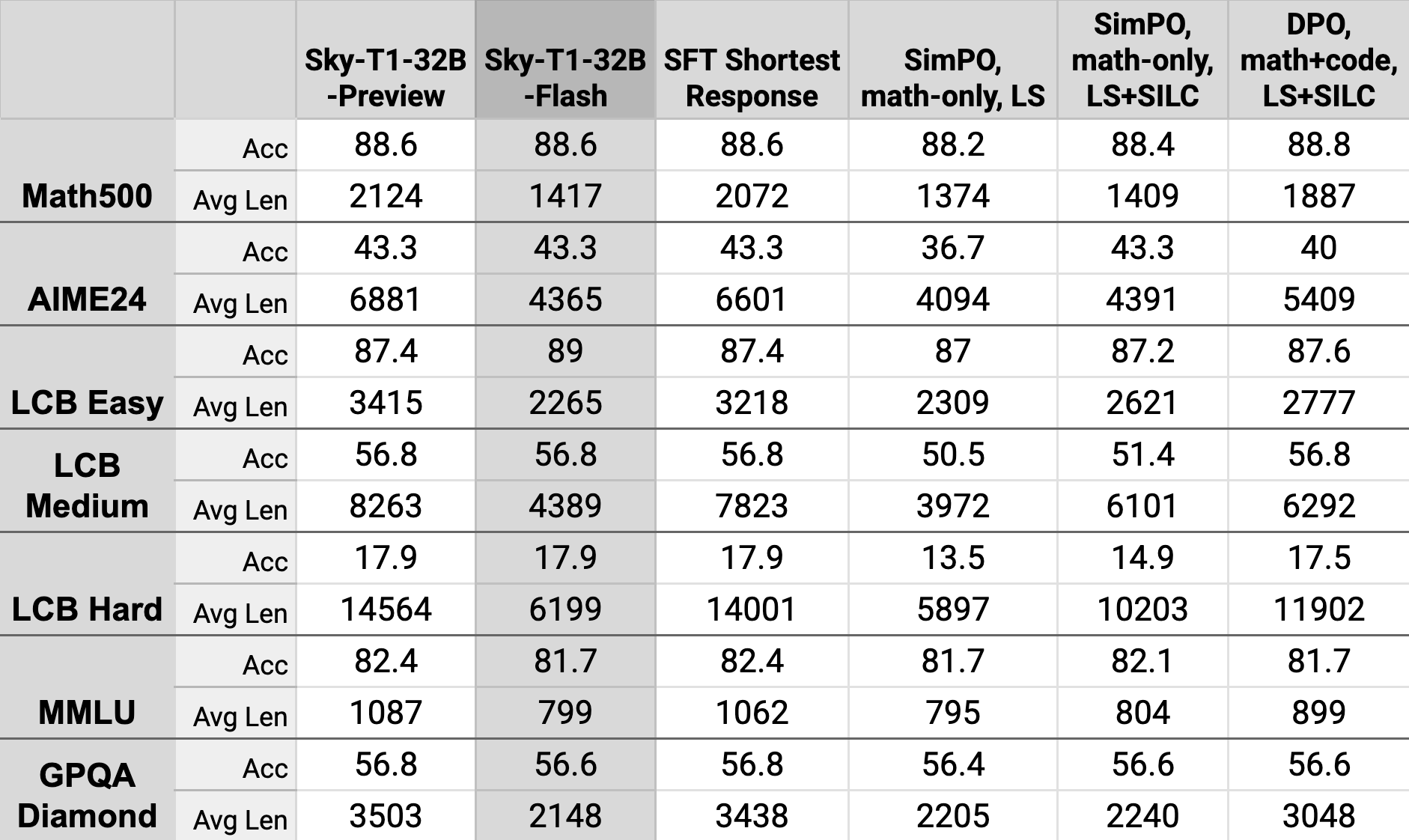
Ablations
We report ablation results for alternative methods and recipes we explored. LS refers to using {Negative: Longest correct example, Positive: Shortest correct example} preference pairs. SILC refers to using {Negative: Short Incorrect example, Positive: Long Correct example}.
Acknowledgement
This work is done at Berkeley Sky Computing Lab with generous compute support from Anyscale, Lambda Labs, and Databricks.
Citation
@misc{reduce_overthinking_2025,
author = {NovaSky Team},
title = {Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy},
howpublished = {https://novasky-ai.github.io/posts/reduce-overthinking},
note = {Accessed: 2025-01-23},
year = {2025}
}