S*: Test-Time Scaling for Code Generation
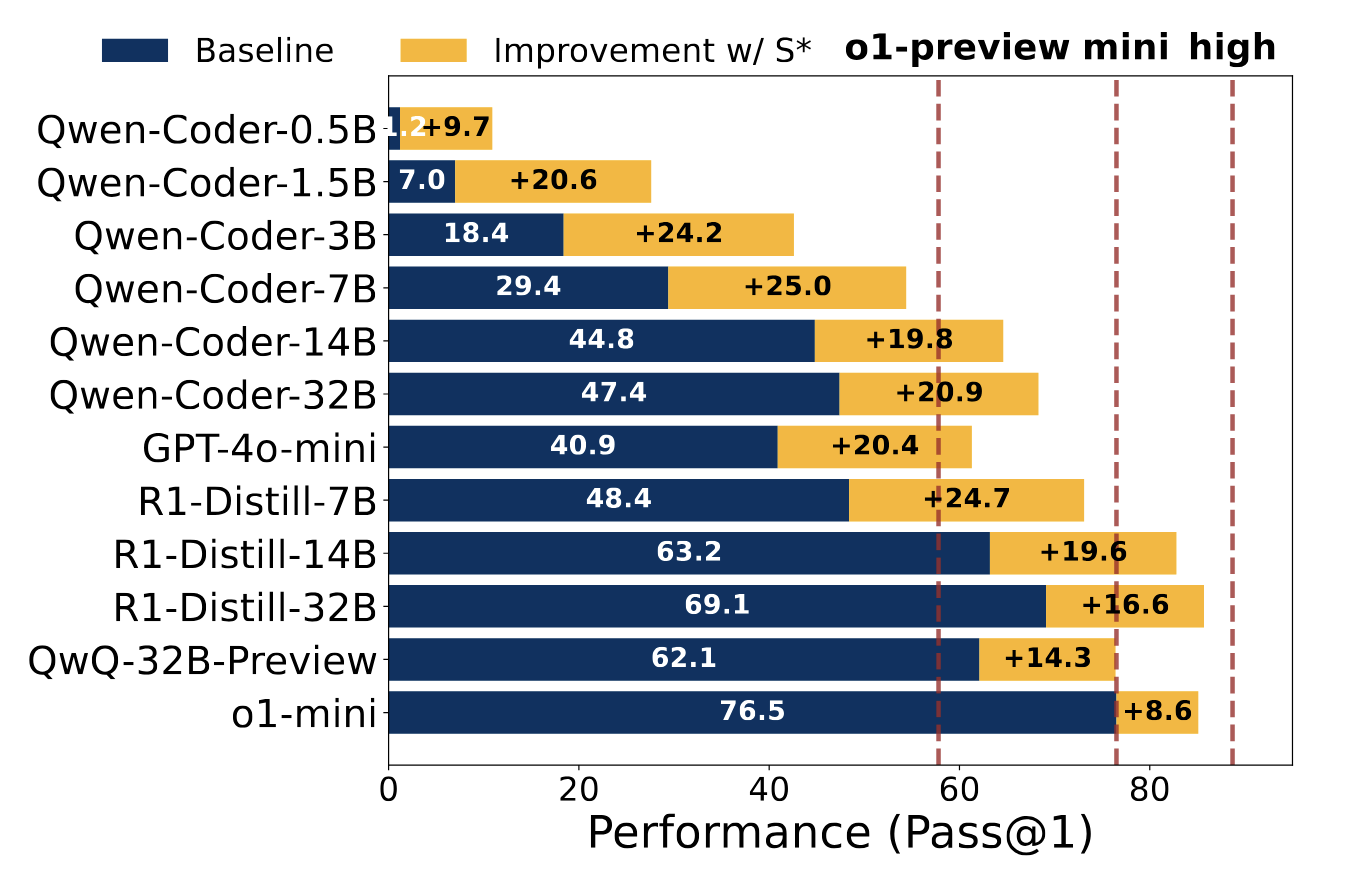
Figure 1: Performance improvement with S* in LiveCodeBench (v2). “Qwen-Coder” denotes “Qwen2.5-Coder-Instruct,” and “R1-Distill” denotes “DeepSeek-R1-Distill-Qwen”. S* consistently improves models across different sizes, allowing non-reasoning models to surpass reasoning models and open models to be competitive with o1 (high reasoning effort).
By: Dacheng Li*, Shiyi Cao*, Chengkun Cao, Xiuyu Li, Shangyin Tan, kurt keutzer, Jiarong Xing, Joey Gonzalez, Ion Stoica — Feb 21, 2025
This blog is a summary of our paper S*: Test-Time Scaling for Code Generation. Please refer to the paper for more details.
Increasing test-time compute for Large Language Models (LLMs) has demonstrated promising gains across various domains. While this approach has been extensively studied in the math domain, its potential in code generation remains underexplored. In this paper, we propose S*, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S* extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. Evaluation across 12 Large Language Models and Large Reasoning Models of varying sizes demonstrates the generality and superior performance of S*: (1) it consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) it enables non-reasoning models to surpass reasoning models—GPT-4o-mini with S* outperforms o1-preview by 3.7% on LiveCodeBench; (3) it further boosts state-of-the-art reasoning models—DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%.
To foster transparency and collaboration, we have open-sourced the full pipeline here.
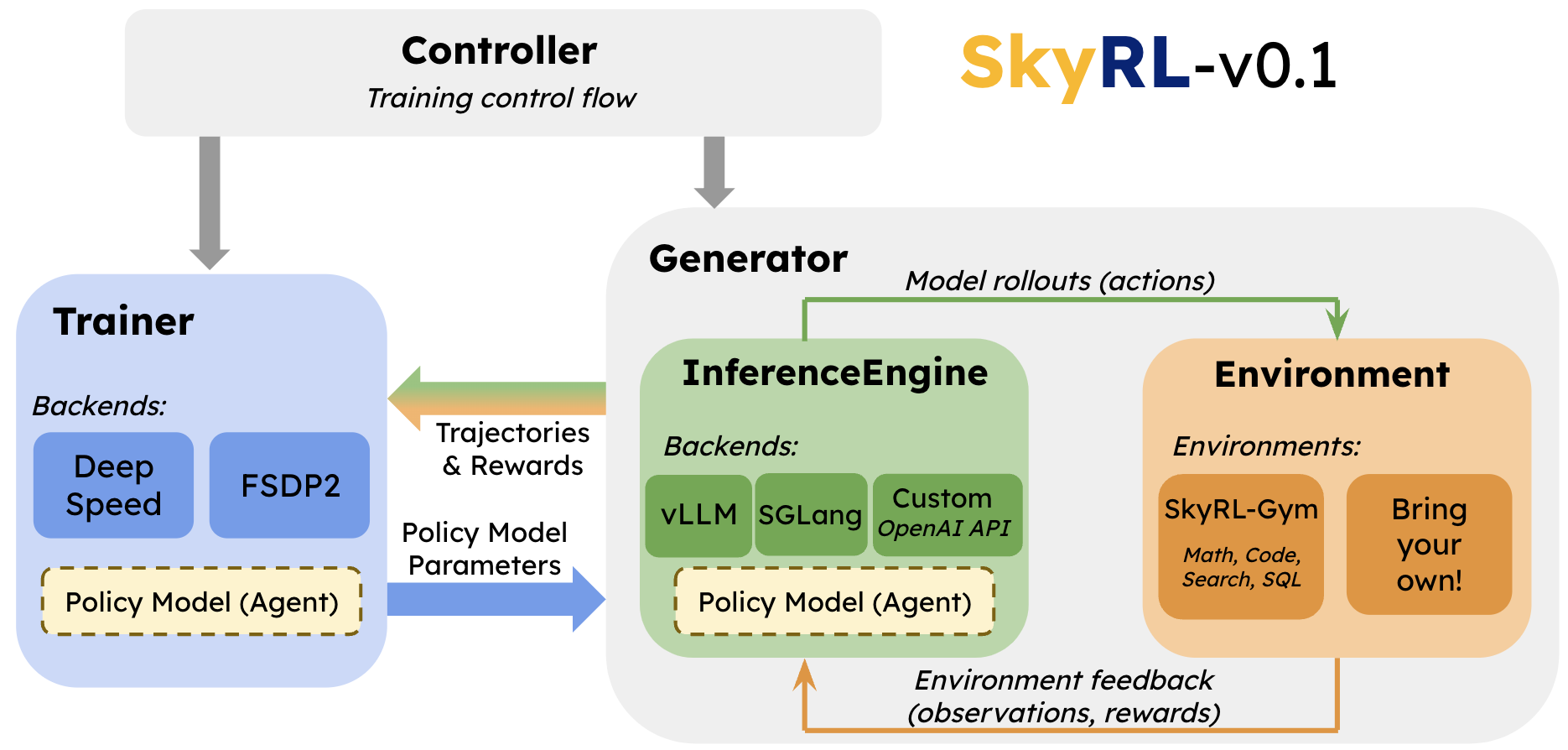
How S* Works
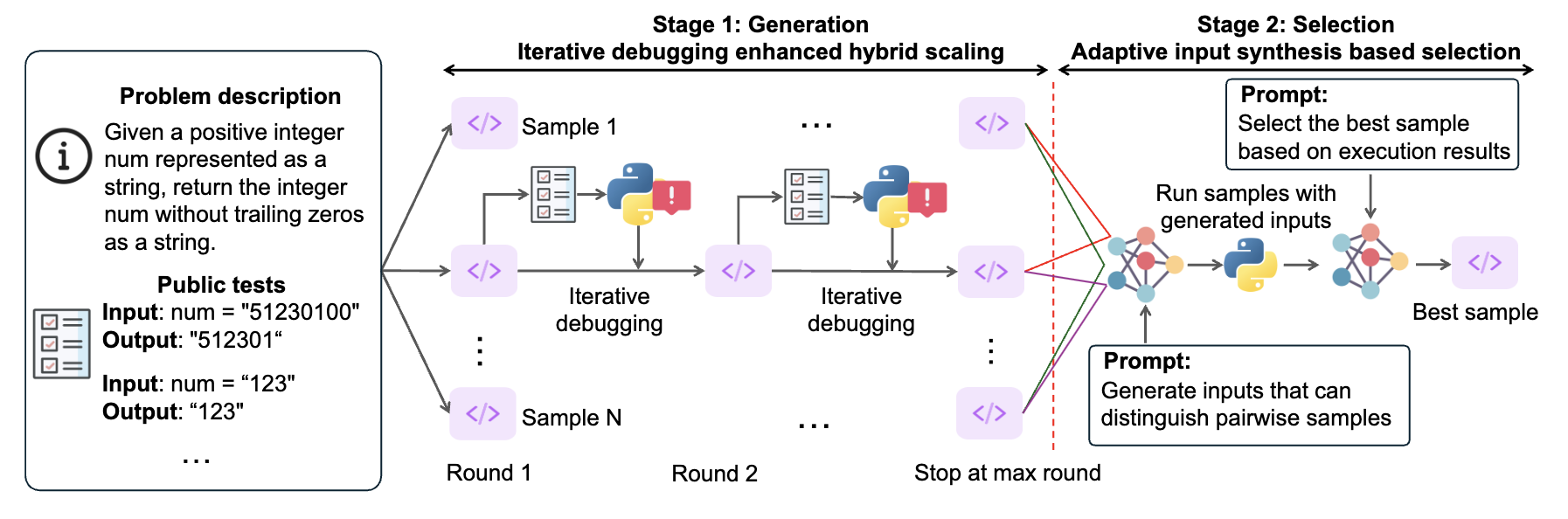 Figure 2: Overview of S*. Stage 1: Generation—S* enhances parallel samples through iterative debugging. Each sample is tested using public test cases executed via an interpreter, with outputs and/or error messages used to guide the next round of sample generation. Stage 2: Selection—S*selects the best sample by prompting an LLM to generate inputs that differentiate between paired samples, then leveraging actual execution results to inform the LLM to determine the optimal choice.
Figure 2: Overview of S*. Stage 1: Generation—S* enhances parallel samples through iterative debugging. Each sample is tested using public test cases executed via an interpreter, with outputs and/or error messages used to guide the next round of sample generation. Stage 2: Selection—S*selects the best sample by prompting an LLM to generate inputs that differentiate between paired samples, then leveraging actual execution results to inform the LLM to determine the optimal choice.
S* operates in two key stages:
Stage1: Generation
We begin by generating multiple candidate solutions through parallel sampling. But instead of simply picking one at random or relying on static evaluation, S* improves coverage by extending parallel scaling with sequential scaling through iterative debugging grounded with execution feedback. Specifically, S* first generates N initial samples independently, leveraging parallel sampling techniques. Each sample is then refined through up to R rounds of sequential revision, informed by execution results on public test cases. The revision process halts once a sample passes all public tests or reaches the maximum number of revision attempts. This iterative debugging allows us to learn from mistakes in real-time, ensuring that the generated code is not only syntactically correct but also functionally robust.
Stage 2: Selection
After generating a set of candidate solutions, the next step is to identify the best one. Since public tests are already used during the generation stage, an additional evaluation is necessary for a reliable selection. Traditional approaches like LLM-as-a-judge that solely relies on pre-trained knowledge or generating static test cases often fall short of producing optimal results.
To overcome the limitations of these methods, we introduced adaptive input synthesis, a hybrid selection approach that combines LLM evaluation with execution-grounded verification. First, we prompt the model to synthesize a set of test inputs. We execute these inputs and cluster the N samples based on their execution outputs. Next, we perform pairwise comparisons across clusters: for each comparison, we prompt the LLM to generate distinguishing inputs, execute both samples using these inputs, and select the superior one based on the execution results. This adaptive selection process, grounded in concrete execution feedback, leads to a more reliable and accurate selection of the best candidate solution.
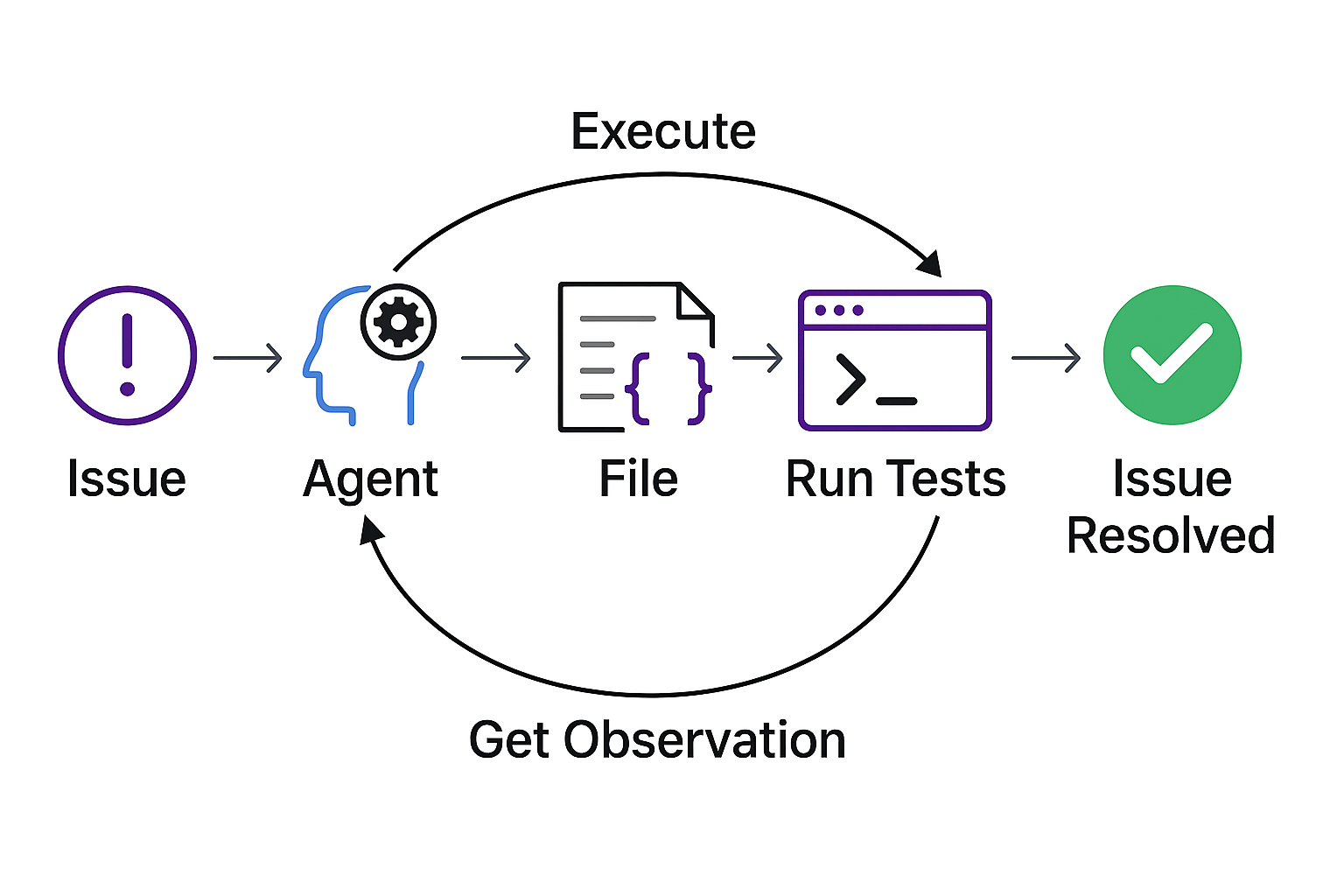
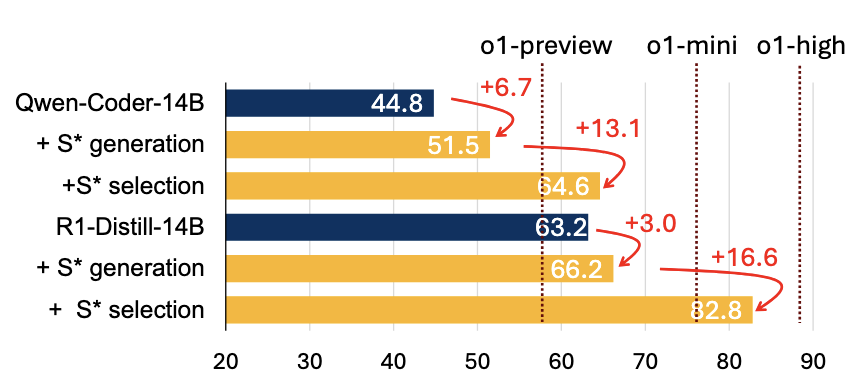 Figure 3: Ablation of S* performance benefits with our two-stage pipeline: Qwen2.5-Coder-14B-Instruct (denoted as Qwen-Coder14B) with S* can surpass o1-preview without S*. DeepSeek-R1-Distill-Qwen-14B (denoted as R1-Distill-14B) with S* outperforms o1-mini without S*.
Figure 3: Ablation of S* performance benefits with our two-stage pipeline: Qwen2.5-Coder-14B-Instruct (denoted as Qwen-Coder14B) with S* can surpass o1-preview without S*. DeepSeek-R1-Distill-Qwen-14B (denoted as R1-Distill-14B) with S* outperforms o1-mini without S*.
Evaluation
In this blog, We evaluated S* across a diverse set of instruction-based and reasoning models, spanning various model families, sizes, and access types (open and closed). More details and benchmark results can be found in the paper.
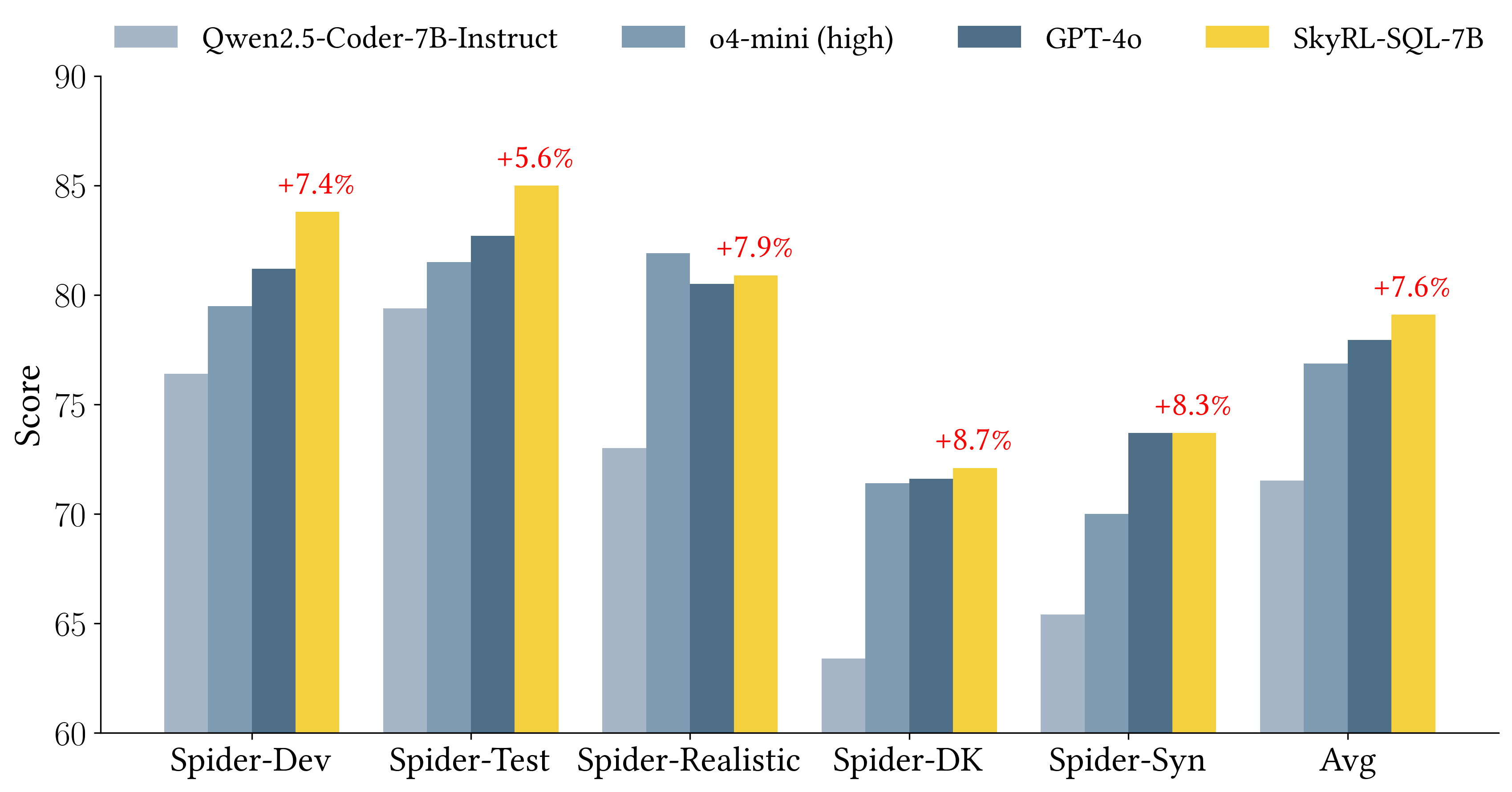
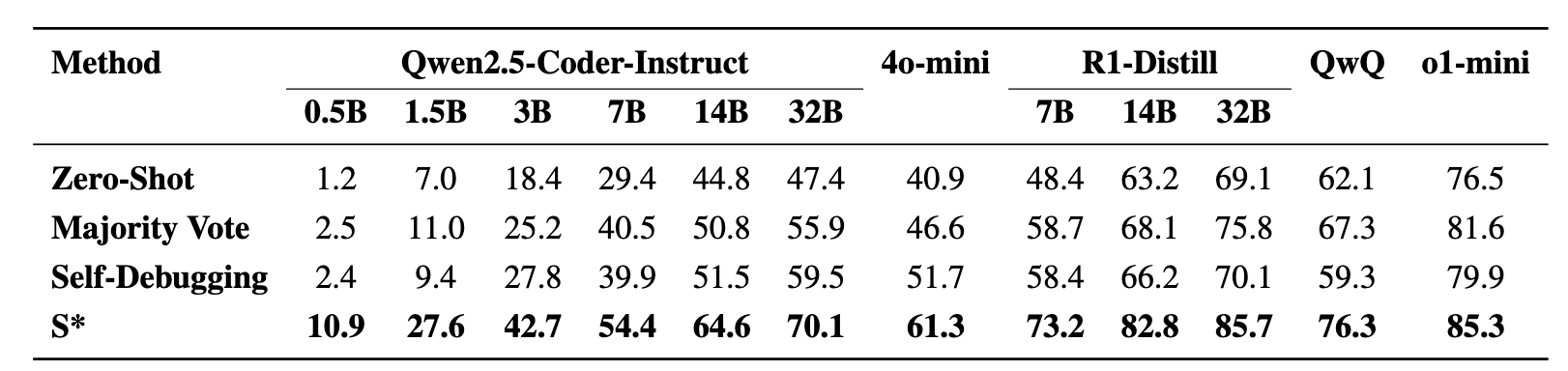 Figure 4: Performance comparison on LiveCodeBench with and without our framework, with other methods.
Figure 4: Performance comparison on LiveCodeBench with and without our framework, with other methods.
Our approach consistently enhances model performance across the board. When applied to models within the same family, our method enables smaller models to outperform larger ones—for instance, a Qwen2.5-7B-Coder-Instruct model integrated with S* outperforms its 32B counterpart without S* by 7%. It also empowers instruction-based models to surpass reasoning models, as shown by one of our smaller models outperforming a leading reasoning model. Furthermore, even the most capable open-source reasoning model, DeepSeek-R1-Distill-Qwen-32B, surpasses o1-mini and achieves near state-of-the-art performance when enhanced with our approach.
We also compare our framework against two popular test-time scaling methods—one based on majority voting, where the model generates multiple samples, clusters them by execution results, and selects a final candidate, and another based on self-debugging, where the model iteratively refines a single sample using public tests. Using consistent hyperparameters for a fair comparison, our framework consistently outperformed both techniques. For the Qwen2.5-Coder series, our method improved performance by 8.4% to 18.2% over the baselines, and for the best performing model, it outperforms the majority voting baseline by 9.9% and the self-debugging baseline by 15.6%.
Citation
@article{li2025s,
title={S*: Test Time Scaling for Code Generation},
author={Li, Dacheng and Cao, Shiyi and Cao, Chengkun and Li, Xiuyu and Tan, Shangyin and Keutzer, Kurt and Xing, Jiarong and Gonzalez, Joseph E and Stoica, Ion},
journal={arXiv preprint arXiv:2502.14382},
year={2025}
}